Using Snowflake and Databricks Together: A Unified Architecture Approach

Abdul Fahad Noori
October 29, 2025




ABSTRACT: Drawing on insights from our consulting engagements with Janus Henderson Investments, this article conveys an approach for the coexistence of Snowflake and Databricks. It’s the pragmatic path forward that brings architectural clarity and aligns responsibilities in hybrid data environments.
Introduction: From Platform Rivalry to Unified Architecture
For years, enterprises have treated Snowflake and Databricks as competitors — one purpose-built for business intelligence, the other for engineering and machine learning. Yet as both platforms mature, the boundaries between them are fading.
Today, many organizations already operate both Snowflake and Databricks.
The more practical question is no longer “Which one is better?” but “How can we use them together as part of a single, coherent architecture?”
That question was at the heart of the recent Datalere webinar, Blending Snowflake & Databricks at Janus Henderson Investments — featuring Mark Goodwin, Data Architect at Janus Henderson Investments, and Michael Speissbach, Manager of Data Architecture & Engineering at Datalere. Moderated by Wayne Eckerson, the session explored how organizations can align Snowflake’s governed analytics environment with Databricks’ flexible engineering and ML capabilities — without duplication or performance drag.
At Janus Henderson, a Datalere client, the hybrid setup pairs the two platforms to meet both engineering and analytics needs. Databricks powers complex transformations, data science, and streaming pipelines, while Snowflake serves as the operational layer for BI and reporting. Together, they form a unified architecture that blends intelligence with governance — allowing each platform to play to its strengths while maintaining a consistent data lifecycle.
This guide distills the key architectural insights from that discussion — how Snowflake and Databricks can complement one another within a single ecosystem, and what this hybrid model reveals about the evolving future of enterprise data platforms.
1. Heritage and Convergence
Two origins, one trajectory
Snowflake and Databricks originated from different ends of the data spectrum.
Snowflake built its reputation as a cloud-native data warehouse—simple, elastic, and optimized for governed analytics and data sharing.
Databricks, rooted in Apache Spark, evolved as an open, flexible platform for data engineering, streaming, and machine learning.
For much of the past decade, their use cases were complementary: Snowflake delivered speed and ease of use for analytics teams, while Databricks empowered data engineers and scientists to experiment, model, and build. As enterprise data ambitions expanded, both platforms began to evolve toward a broader middle ground.
Snowflake introduced Snowpark, Cortex, and Container Services to expand into Python, AI, and application development workloads. Databricks, meanwhile, added SQL analytics, serverless compute, and Unity Catalog to simplify governance.
What the data shows
Findings from ETR’s Q2 2024 enterprise survey (via SiliconANGLE) highlight how widespread this overlap has become:
Roughly 60% of Databricks customers also use Snowflake, and 40% of Snowflake customers run Databricks.
28% plan to shift more workloads toward Databricks, 19% toward Snowflake, and 44% have no plans to change their mix.
Only 4 % expect to fully phase out Snowflake, and just 2 % the reverse.
This data underscores a pragmatic reality: most enterprises are using both, optimizing each for what it does best. Databricks remains strong in engineering and AI, while Snowflake excels in governed analytics and performance. Both companies are expanding into open-source governance through standards like Apache Iceberg to ensure interoperability.
For many teams, this shift has reframed architecture work—from platform management to ecosystem design, where interoperability and stewardship matter as much as raw performance.
Our experts can help you assess whether Snowflake and Databricks overlap, where they’re distinct, and how to align them without duplication. You can book a exploratory session here.
Where each stands today
In the diagram below, we can see how the two platforms currently align. Each retains distinct strengths, yet their trajectories are converging fast. Databricks offers deeper control for engineering and model-driven workloads; Snowflake simplifies orchestration, scalability, and data sharing. The overlap between these capabilities is growing with every release—making a unified architecture not only possible but increasingly practical.
Note: This comparison reflects Datalere’s interpretation based on hands-on experience with both platforms. The lines are evolving rapidly, and every organization’s use case will shape its own version of this balance.

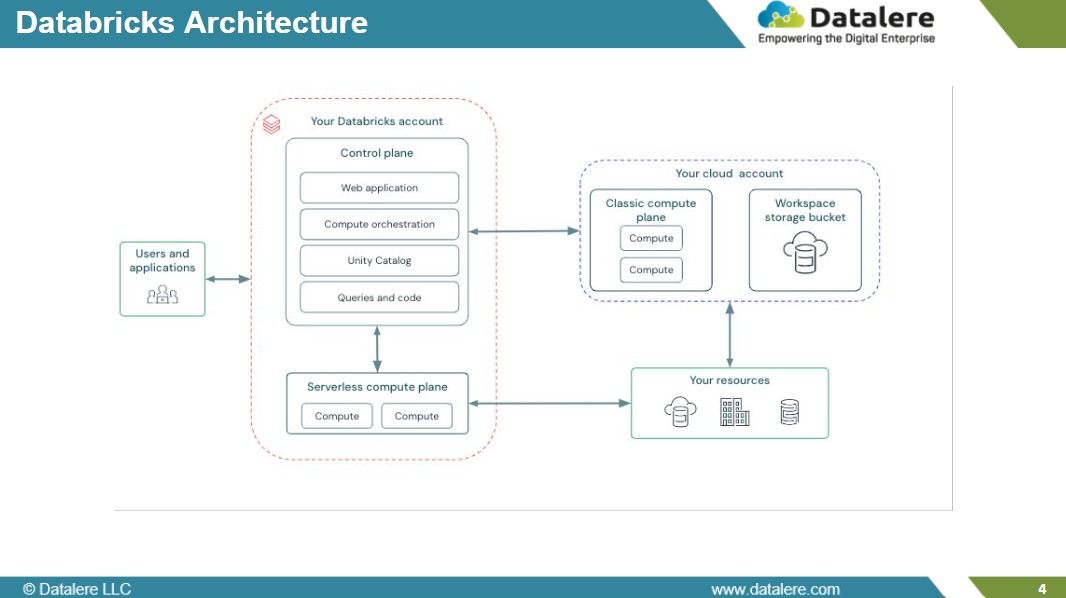
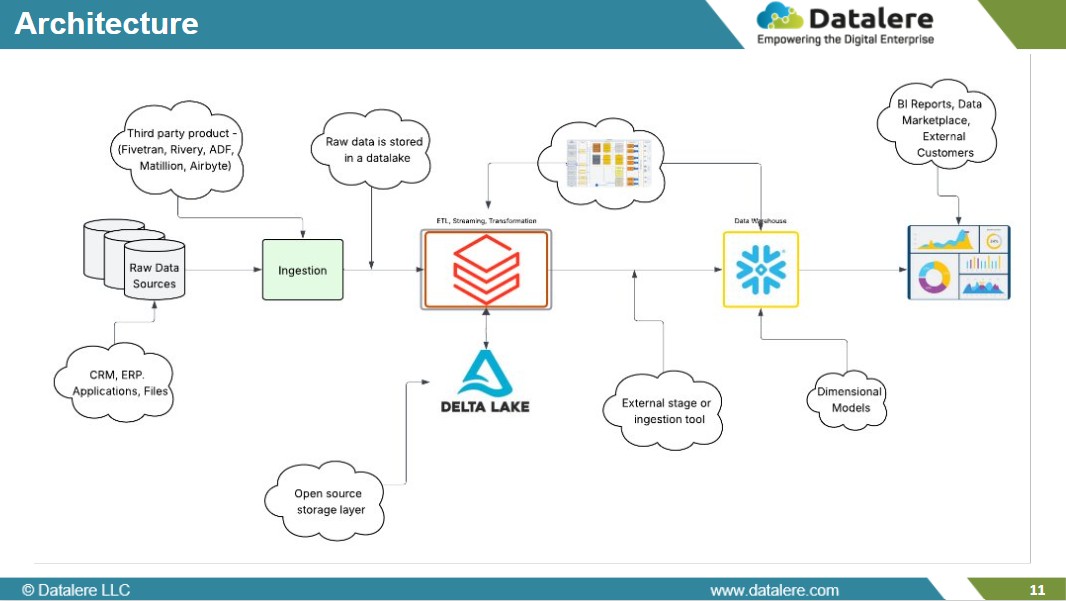
2. Databricks Architecture
Databricks is designed for flexibility — giving data teams control over where and how workloads run.
Its architecture separates management from execution through two layers.
The control plane, managed by Databricks, handles workspaces, jobs, and governance.
The compute plane, deployed in the customer’s cloud account, executes processing while keeping data within the enterprise boundary.
This separation provides flexibility in cost management, networking, and security—features valued in complex data environments. Over time, Databricks has evolved from its Spark roots into a broader platform for data engineering and machine learning, introducing Delta Lake, Autoloader, and serverless compute to simplify ingestion and orchestration.
Its notebook-based development model encourages iterative experimentation, making Databricks a natural fit for streaming, advanced transformations, and model training.
These architectural traits explain why Databricks often functions as the engineering and intelligence layer within modern data ecosystems—but its full value emerges when connected with complementary platforms designed for analytics and operational reliability.
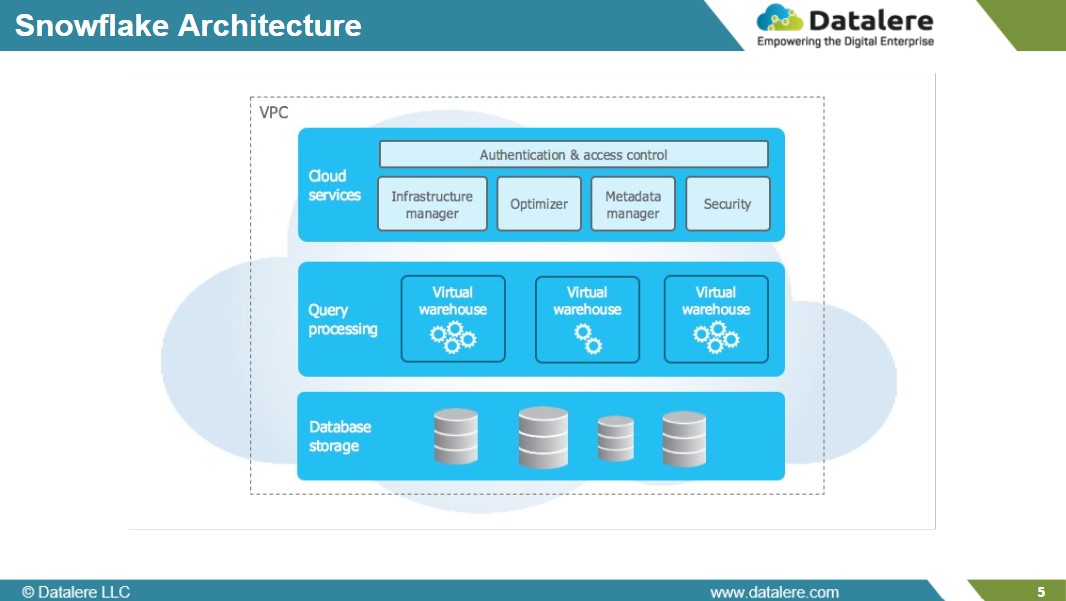
3. Snowflake Architecture
Snowflake takes the opposite path—built for managed simplicity and predictable performance.
Snowflake’s cloud-native design eliminates almost all infrastructure management through three core layers:
The storage layer, which maintains data in Snowflake-managed cloud storage.
The compute layer, composed of independently scalable virtual warehouses.
The cloud services layer, which manages orchestration, metadata, and optimization.
This architecture delivers Snowflake’s signature traits: quick spin-up, automatic scaling, and consistent query performance without manual tuning. Its fully managed nature appeals to teams prioritizing governance and fast access over environment control.
Snowflake continues to expand its ecosystem—with Snowpark for code-driven data engineering and Snowflake Marketplace for external data access—but its defining strength remains operational efficiency and user accessibility.
In unified architectures, these characteristics make Snowflake an ideal delivery and analytics layer—a foundation for governed BI and data sharing that relies on upstream transformation engines to feed it high-quality, well-modeled data.
4. Platform Challenges and Trade-offs
Every architecture choice involves trade-offs, and both platforms reveal complementary gaps that explain why many enterprises deploy them together.
As Michael Speissbach and Mark Goodwin discussed during the webinar, Snowflake’s managed simplicity comes at the cost of flexibility.
It offers limited visibility into compute configuration or tuning, which limits control for teams that want to customize execution environments.
Its proprietary SQL extensions—features like QUALIFY and FLATTEN—make workloads highly efficient within Snowflake but more challenging to port elsewhere.
And while Snowflake has added Snowpark and Cortex for Python and AI, its compute isolation makes large-scale model training more complex than in Databricks.
Databricks, on the other hand, trades control for complexity.
Spark overhead and cluster management can feel heavy for smaller workloads.
Its notebook-centric workflow accelerates experimentation but can create code-reuse and dependency-management challenges without strict engineering standards.
Historically, governance was fragmented across workspaces—though the Unity Catalog has started to consolidate permissions and lineage.
Governance remains a shared frontier. Both platforms are expanding their native capabilities, but most enterprises still rely on third-party catalog and lineage tools to maintain end-to-end visibility across hybrid environments.
In essence, Snowflake optimizes for consistency while Databricks optimizes for configurability. Recognizing—and designing around—these inherent tensions is what makes a unified architecture not just possible, but necessary.

5. Why a Unified Architecture
The trade-offs we outlined earlier are design tensions that, when aligned, create balance across the data lifecycle.
As Michael Speissbach summarized during the session, Databricks is where you build intelligence; Snowflake is where you operationalize it.
This relationship is what turns two distinct platforms into a cohesive architecture.
Here’s how the balance works in practice:
Best of both worlds: Databricks drives the engineering and intelligence layer—handling transformations, streaming, and machine learning—while Snowflake provides the operational backbone for analytics, governance, and reporting.
Optimized workloads: Databricks executes compute-heavy tasks like feature engineering and model training, freeing Snowflake to focus on fast, concurrent analytics without contention or cost spikes.
Multi-persona enablement: Each team operates in its ideal environment—data scientists and engineers in Databricks, analysts and business users in Snowflake—while accessing the same curated, governed data sets.
End-to-end lifecycle continuity: Instead of multiple siloed systems, data flows seamlessly from ingestion and transformation in Databricks to analysis and sharing in Snowflake, ensuring a consistent lineage from raw to refined data.
Future-ready flexibility: Open formats such as Delta Lake and Apache Iceberg, along with unified governance through Unity Catalog and Horizon, make it easier to evolve architectures over time without introducing dependency or drift.
In this model, the challenges of each platform are absorbed and balanced by the other.
Databricks brings adaptability and depth to data creation; Snowflake brings reliability and reach to data consumption.
Together, they form a unified framework that supports both innovation and control—an end-to-end architecture designed for the realities of modern enterprise data.
If your organization is exploring a similar model, schedule a chat—we’re always up for comparing architectures and lessons from the field.
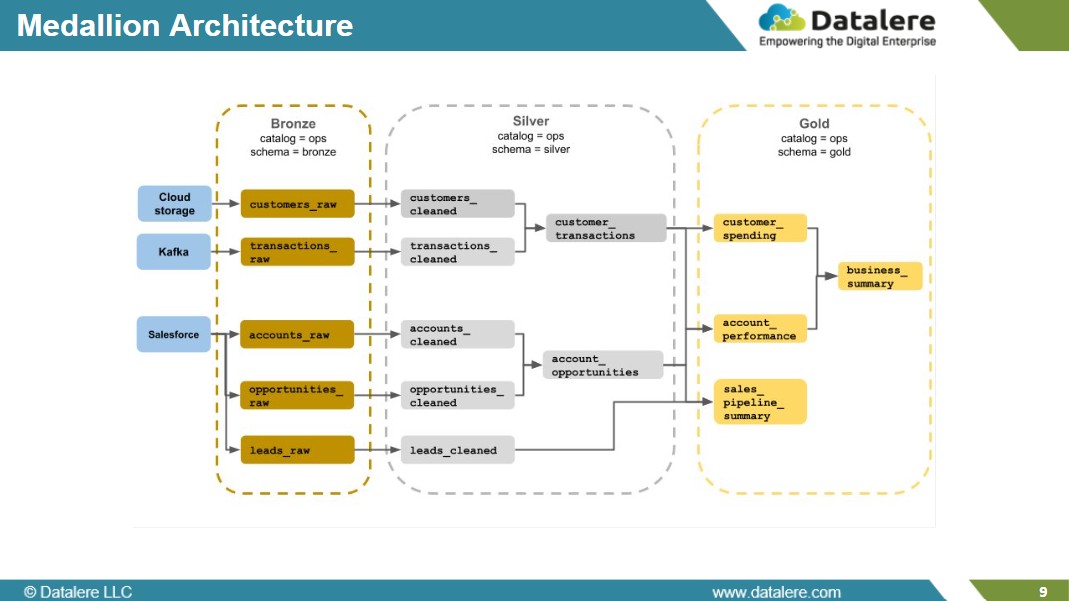
6. The Janus Henderson Use Case: Medallion Architecture in Practice
At Janus Henderson Investments, the unified architecture follows a Medallion pattern—a layered design that organizes data by its level of refinement and readiness for use. Each layer exists within a clearly defined schema (ops.bronze, ops.silver, and ops.gold), creating a predictable flow from ingestion to analytics.
Bronze (Raw Layer)
The ops.bronze schema stores ingested data from multiple internal systems and third-party APIs. Data here is largely unrefined—captured as-is to ensure completeness, traceability, and auditability. This layer forms the foundation for all downstream processing, maintaining full lineage from original sources.
Silver (Curated Layer)
The ops.silver schema contains cleaned, standardized, and enriched data sets. Transformations applied here enforce schema consistency, deduplication, and validation. This is the analytical core of the environment—data in this layer is reliable enough for modeling, aggregation, and downstream publication.
Gold (Business-Ready Layer)
The ops.gold schema contains governed, high-trust data optimized for business use. These are the curated, documented data sets consumed by BI and analytics tools such as Power BI and Alteryx, and shared through Snowflake for broader organizational access. Access policies ensure that only approved data objects flow into business-facing environments.
As Michael Speissbach noted, this model creates a data contract between engineering and analytics teams: each layer is accountable for a specific quality threshold, and data never needs to be rebuilt downstream.
The result is a continuous, governed lifecycle—data enters once, improves through structured refinement, and becomes ready for every stakeholder, from modelers to decision-makers.
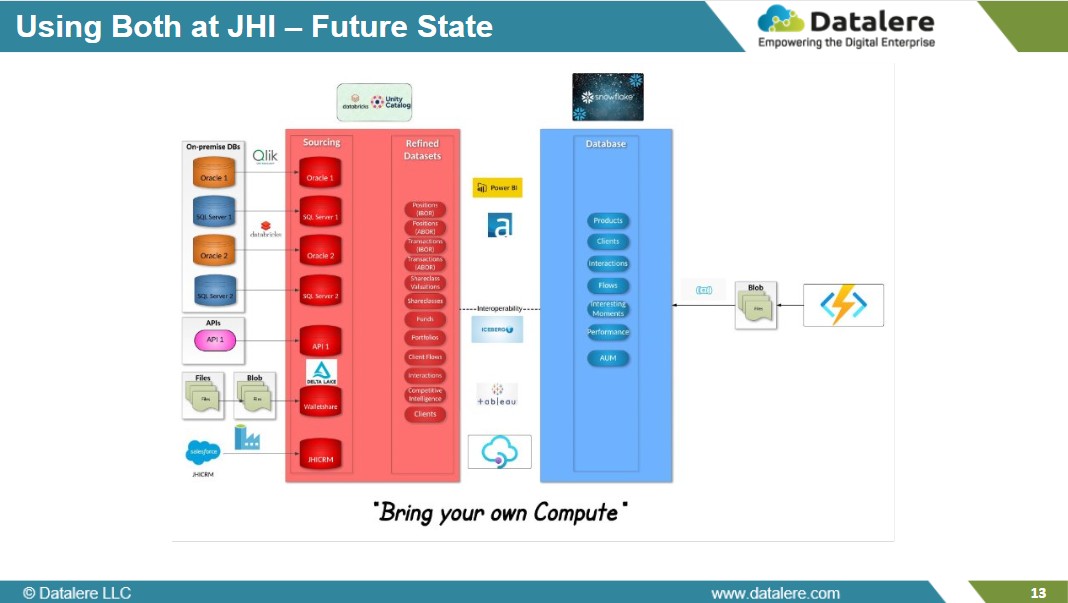
7. The Janus Henderson Case Study
Current-State Hybrid Architecture
Building on its medallion framework, Janus Henderson Investments has operationalized a hybrid ecosystem that unifies legacy data sources, cloud services, and governed analytics into a single, traceable flow.
Upstream data still originates from multiple on-prem systems and SaaS applications, delivered through secured APIs into a centralized data lake. These ingestion streams preserve source lineage and metadata, forming the foundation of the Bronze layer within Databricks. From there, automated orchestration pipelines—scheduled and monitored within Databricks—perform cleaning, conformance, and enrichment tasks that feed the Silver layer, where business logic and validation rules are applied.
At defined checkpoints, curated datasets are registered in Unity Catalog and handed off to Snowflake through scheduled batch and streaming jobs. This contract-based interface ensures that downstream teams only access standardized, version-controlled data objects. Once inside Snowflake, the Gold layer delivers structured data marts for BI, reporting, and data-sharing use cases.
The architecture maintains segregation of compute and storage: Databricks manages transformation and machine-learning workloads on scalable clusters, while Snowflake handles query concurrency and user-level governance for business consumption. Despite this division, lineage remains continuous—tracked from ingestion through modeling to consumption—so audit and compliance teams can verify every data movement.
Governance operates as a distributed fabric.
Unity Catalog centralizes ownership and permissions for datasets created in Databricks, while Snowflake’s role-based access controls, masking policies, and row-level security extend those protections downstream. Shared metadata definitions synchronize the two environments, ensuring policy consistency even across different compute domains.
This design represents pragmatic modernization: legacy and cloud coexist, bound by clear orchestration logic and a common governance model. The result is a controlled, end-to-end data lifecycle that accelerates delivery while maintaining enterprise-grade auditability.

Future-State Direction
The next phase introduces open-table formats such as Apache Iceberg to create a bring-your-own-compute model.
In this design, both Databricks and Snowflake will read and write against the same curated storage layer, eliminating replication and simplifying cross-platform governance. Workloads can execute where they perform best—streaming and model training in Databricks, interactive analytics in Snowflake—while drawing from a single physical data source.
Adopting Iceberg also future-proofs the stack: new compute engines can plug into the same storage layer without schema rewrites or data movement. Combined with existing governance controls, this approach strengthens flexibility while preserving trust.
Business Impact
Janus Henderson’s hybrid model demonstrates how unification delivers tangible results:
Accelerated insight delivery through automated, contract-based orchestration.
End-to-end lineage visibility supporting financial-sector audit and compliance.
Operational efficiency by aligning compute to workload type and reducing redundant storage.
Sustainable modernization, allowing on-prem systems to coexist while migrating strategically toward open, cloud-first infrastructure.
Together, these outcomes show how a unified data architecture can evolve within real-world constraints: balancing performance, governance, and adaptability without disruption.
As you evaluate similar goals, a conversation with our architects can help uncover how much value your current model creates and where refinements could multiply it.
Book a brief discussion with our architects.
8. Strategic Outlook — Planning for Convergence
The lines between Snowflake and Databricks continue to blur.
Each release brings new overlap — Databricks strengthening its analytics and governance capabilities, Snowflake moving deeper into data engineering and AI.
As SiliconANGLE observed in its analysis of ETR’s enterprise data,
“While the point of control is shifting to the governance layer, the source of value is moving toward building data apps.”
The observation reflects a subtle but important change: what once defined a data platform is now defined by what it enables.
Open standards such as Apache Iceberg and Delta Lake reinforce this shift.
They allow multiple compute engines to operate on the same data without duplication, extending flexibility across platforms and clouds.
At the same time, hyperscalers — AWS, Azure, and Google Cloud — are expanding their native data and AI ecosystems.
Many enterprises are testing how far they can consolidate within those environments, not to replace Snowflake or Databricks, but to simplify architectures and bring analytics closer to where the data already lives.
As these ecosystems continue to intersect, success will depend less on connecting platforms and more on how teams design for flexibility — balancing workloads, managing costs, and maintaining consistency across systems that evolve at different speeds.
Those are the principles that turn a hybrid setup into a sustainable architecture.
We’ll explore this mindset in greater depth in our next article,
“Five Design Principles for a Unified Snowflake + Databricks Architecture.”
And as the platforms continue to converge, one question remains:
When every layer becomes interoperable, what truly defines the architecture of tomorrow?
Abdul Fahad Noori
Fahad enjoys overseeing all marketing functions ranging from strategy to execution. His areas of expertise include social media, email marketing, online events, blogs, and graphic design. With more than...
Talk to UsYou Might Also Like



