Five Design Principles for a Unified Snowflake + Databricks Architecture

Michael Spiessbach
October 29, 2025




ABSTRACT: Operating Snowflake and Databricks together requires discipline. This guide distills five principles: Store Once, Serve Many, Separate by Workload, Govern Consistently, Control Cost Through Isolation, and Design for Observability. Five principles to keep a hybrid architecture clear, governed, and cost-aware as it scales.
Introduction
Integrating Snowflake and Databricks into a cohesive architecture is less about stitching tools together and more about designing for continuity. The aim is to move from parallel stacks to a coordinated environment where data progresses from ingestion to analysis without duplication, drift, or guesswork.
Part One explored why the two platforms are converging and how enterprises are combining strengths to cover the full data lifecycle. This continuation focuses on how that convergence becomes operational: the design disciplines that make a hybrid environment work reliably in practice.
At Janus Henderson Investments, these ideas matured through implementation. The resulting patterns emphasize coherence—shared foundations, aligned workloads, consistent governance, cost visibility, and a feedback loop that keeps the whole system intelligible as it evolves.
1. Store Once, Serve Many
A unified environment gains stability when its data foundation is singular and accessible. Modeling data once and storing it in an open format ensures that transformation, analytics, and machine learning draw from the same curated layer.
In practice, this means using open table formats—notably Delta and Apache Iceberg—to keep schema, metadata, and versioning aligned across compute engines. Both Snowflake and Databricks can interact with the same physical data without replication. As structures evolve, changes propagate through shared metadata rather than being re-implemented in multiple places.
The effect is cumulative. Engineering teams concentrate on accuracy and transformation quality, while analytics teams work from a layer that reflects those improvements automatically. Lineage remains intact, reconciliation cycles shrink, and new consumers onboard against a consistent model. Over time, the shared storage layer becomes a durable reference point for the entire ecosystem, enabling growth through refinement instead of proliferation.
2. Separate by Workload
Once data sits on a shared foundation, efficiency depends on placing each workload where it performs best. The stages of the lifecycle—ingestion, transformation, data science, and consumption—carry different performance characteristics and service expectations. Aligning them thoughtfully improves both speed and predictability.
A pragmatic split has emerged in many hybrid environments. Databricks supports ingestion pipelines, complex transformations, streaming, and model development—work that benefits from flexible compute and code-centric iteration. Snowflake provides the governed analytics and distribution layer, optimized for concurrency and straightforward access.
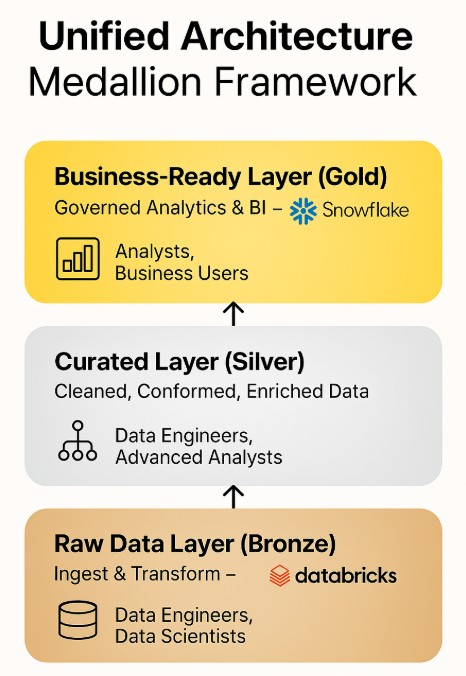
This division maps cleanly to a medallion framework:
Bronze captures raw data for completeness and auditability.
Silver standardizes, validates, and enriches for analytical readiness.
Gold publishes business-ready datasets for reporting and sharing.
The handoffs are explicit. Ownership at each tier is clear, and performance tuning happens where it matters: throughput and logic in Databricks; accessibility and concurrency in Snowflake. By separating execution along natural boundaries, the architecture avoids contention while keeping data flowing in a straight line from source to decision.
3. Govern Consistently
A hybrid architecture holds together when governance stays consistent across every stage of the data lifecycle. Policies, permissions, lineage, and classification should remain consistent as assets move between platforms; otherwise, integration becomes fragile.
Consistency emerges from aligned cataloging and access controls. Unity Catalog establishes ownership, permissions, and lineage for datasets produced in Databricks; Snowflake’s governance framework—roles, masking, row-level policies—maintains control at the consumption edge. Synchronizing metadata between these layers keeps definitions coherent and traceable across the full path from transformation to analysis.
The result is practical confidence. Engineers and data scientists can work with data confidently, knowing that access controls and lineage stay consistent from source to consumption. Analysts access governed datasets without raising questions about provenance. Compliance teams trace activity without combing through disconnected logs. Governance is not an afterthought bolted onto pipelines; it is part of how the system functions day to day.
4. Control Cost Through Isolation
Elastic compute offers flexibility, but without limits it can blur accountability for cost and performance. Isolation restores that clarity: workloads run in defined pools, scaled for their specific purpose.
In Databricks, clusters are provisioned for distinct functions—ingestion, transformation, training—and automatically shut down when idle. In Snowflake, warehouses are sized and scheduled by purpose—ETL, development, BI—and monitored independently.
This structure yields two advantages. First, transparency: usage can be traced to specific teams, domains, or projects, enabling chargeback and evidence-based optimization. Second, stability: heavy processing jobs never compete with interactive analytics.
Serverless options simplify elasticity even further, but isolation is what keeps consumption accountable and performance predictable as usage scales.
5. Design for Observability
As ecosystems expand, visibility becomes the mechanism that sustains reliability. Observability connects the moving parts, showing how data flows, how processes behave, and where attention is needed.
Embedding observability into orchestration creates a continuous feedback loop. Databricks pipelines surface execution status, durations, and dependency health; Snowflake logs reveal query performance, warehouse activity, and user patterns. When combined with lineage, these signals allow teams to diagnose issues in context—tracing a failed step or a slow report across systems to the precise dependency that needs adjustment.
Over time, this feedback shapes better defaults: scheduling that reflects real usage, data contracts that catch schema shifts earlier, and capacity settings tuned to actual demand. The architecture becomes adaptive—still governed, still predictable, yet responsive to how people and workloads actually use it.
Conclusion
The strength of a unified Snowflake + Databricks architecture comes from how its parts reinforce one another. A single, open foundation anchors consistency. Workload separation aligns execution with purpose. Governance continuity preserves trust as data moves. Isolation keeps scale and cost intelligible. Observability turns operations into a learning system.
These practices have taken shape through implementations—including at Janus Henderson—where teams favored coherence over one-size-fits-all solutions. They point toward an approach that is steady rather than rigid: open to platform evolution, clear about responsibilities, and measured in how change is introduced.
If you’d like to explore how these principles apply to your Snowflake + Databricks environment, our architects can walk through your current setup and highlight areas to refine or simplify. Book a short discussion here.
Michael Spiessbach
Michael has a deep background in data architecture and engineering. His projects have included architecting and building a complex AI-based system for processing unstructured text documents, optimizing the data migration...
Talk to UsYou Might Also Like



